
“Sono come il fiume che scorre”
Paolo Coelho
L’elaborazione di un flusso di dati può essere rappresentata nell’immaginario collettivo come un fiume che scorre verso la sua foce. Infatti, allo stesso modo in cui l’acqua scorre attraverso un fiume, così fanno i pacchetti di informazioni nel flusso infinito della loro elaborazione in tempo reale.
Nello scenario tecnologico moderno si trovano molti esempi in cui questo “flusso” di dati è rappresentato. Pensiamo ad esempio ai dati provenienti da sensori montati su macchinari industriali, le attività genarate dagli utenti sui social, o ancora le informazioni geospaziali rilevate in tempo reale dalle autovetture. Sono solo pochi esempi che esprimono come il mondo reale sia un continuo produttore di dati, aggiornati nell’ordine dei millisecondi.
Il Data Streaming, o Stream Processing, è l’approccio che nasce allo scopo di permettere l’elaborazione di questi “dati in movimento”.

Apache Kafka, il motore di stream processing dalle molteplici funzionalità
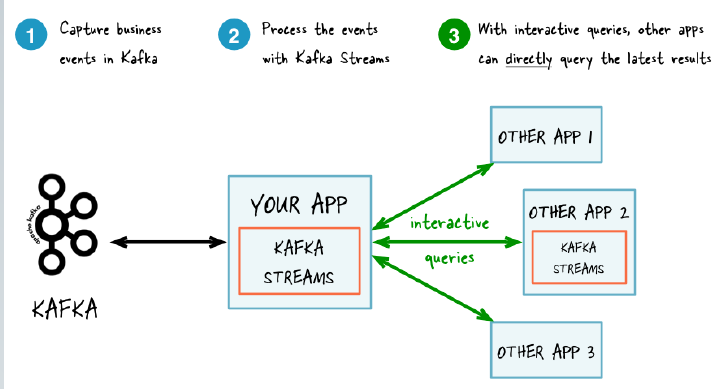
Apache Kafka è un motore di stream processing che permette di costruire pipeline di dati in real-time e applicazioni in streaming. Riceve dati da diversi tipi di sorgenti (detti producer), e li elabora rendendoli disponibili ai riceventi (consumer). All’interno dell’architettura è possibile costruire applicazioni attraverso la libreria Kafka Streams per effettuare operazioni di filtraggio e arricchimento dati.

Kafka è stato scelto da grandi aziende, tra cui Linkedin, Twitter, Netflix e Modzilla per gestire e elaborare grandi volumi di dati.
L’elevata flessibilità, scalabilità e tolleranza agli errori di questa piattaforma open source risulta interessante per l’utilizzo con le applicazioni più disparate. In particolare, però, Apache Kafka risulta adatto per svolgere le seguenti attività:
- Storage Distribuito: consente la memorizzazione dei messaggi per prevenire la perdita dei dati, con la facoltà di stabilire un preciso tempo di conservazione degli stessi
- ETL (Extract, Transform, Load): raccolta, trasformazione e caricamento del dato su altri sistemi. Grazie al contributo di Kafka Connect è disponibile una serie di connettori dedicati (Elasticsearch, NEO4J, Cassandra ecc)
- Stream Processing: capacità di effettuare operazioni sui dati in tempo reale, agendo direttamente sul dato durante il flusso
Sulla base di queste operazioni Apache Kafka viene utilizzato in architetture applicative per diversi scopi e contesti:
- IoT, sensor data analysis: possibilità di gestire le enormi quantità di dati generate dai sensori con bassissima latenza.
- Microservizi e comunicazione asincrona: la piattaforma può essere utilizzata come strumento per lo scambio di messaggi asincroni in un ecosistema di microservizi.. Velocizza le comunicazioni tra le applicazioni e riduce al minimo il rischio di perdita di informazioni garantisce anche un alto livello di fault tolerance.
E per ultimo, ma non ultimo: lo stream processing, tramite il quale è possibile apportare modifiche o trasformazioni dei dati durante il flusso, in tempo reale.

Apache Kafka: la soluzione ideale per l’elaborazione in streaming
Come anticipato in precedenza Apache Kafka si offre come una delle soluzioni più performanti e scalabili per il data streaming. Infatti:
- permette infatti di superare un modello di elaborazione di dati in Batch, eseguita in background e a intervalli prestabiliti.
- fornisce un processing e un arricchimento dei dati in real time, garantendo al contempo robustezza e semplicità d’uso.
Tramite Api Stream si ha un strumento che rende più immediata l’elaborazione del flusso di messaggi.
Vengono infatti semplificate:
- operazioni senza stato, come filtraggio e trasformazione dei messaggi di flusso
- operazioni con stato, come join e aggregazione in una finestra temporale
Kafka permette così di operare Real time analytics, eseguire monitoraggio e ottenere il maggior valore possibile dai dati elaborati in streaming.

Casi d’utilizzo di Apache Kafka per il Data Streaming
Ci sono molte modalità di utilizzo per il Data Streaming a seconda della diversità del contesto d’uso. Prendiamo ad esempio un sito web di viaggi, sul quale vanno aggiornati prezzi di hotel e voli che cambiano continuamente. Ad ogni utente deve arrivare un determinato messaggio con l’informazione in questione. Tramite Apache Kafka ogni componente ottiene la copia del messaggio, poiché tutti i nodi di un singolo sistema di abbonati formano un singolo gruppo di consumatori.
Tutte le attività di un sito Web (visualizzazioni di pagina, ricerche o altre azioni che gli utenti possono intraprendere) possono essere monitorati e analizzati tramite Kafka, dato che in origine era stata sviluppata per fare questo tipo di operazioni su Linkedin. Il feed può essere elaborato in tempo reale per ottenere informazioni sul coinvolgimento degli utenti, sui drop-off, sui flussi di pagine e così via.
Le funzionalità di Data Streaming di Kafka si rivelano utili anche per elaborare in tempo reale dati sulla posizione provenienti da GPS o dispositivi smartphone relativi. ad esempio, al percorso di un veicolo. I dati in arrivo possono essere pubblicati su argomenti Kafka ed elaborati con l’API Stream.

Nell’articolo della prossima settimana, dedicato interamente ai casi di uso e contesti d’applicazione del Data Streaming, e che sarà pubblicato sulla nostra pagina dedicata, approfondiremo ancora di più i vari ambiti dove Apache Kafka può rivelarsi fondamentale per l’elaborazione del dato in real time.
Fonti:
medium.com, how to know if apache kafka is right for you
towardsdatascience.com, intro to streaming data and apache kafka
Img da www.01net.it, stream dati apache kafka
Vuoi saperne di più?
Se desideri approfondire l’approccio Data Streaming e conoscere nel dettaglio vantaggi e potenzialità di Apache Kafka contatta Seacom.