
In questo articolo torniamo a parlare di tecnologie che ci stanno particolarmente a cuore, e rappresentano due delle soluzioni opensource più performanti nella scelta Seacom per le architetture software. Parliamo di Apache Kafka e Dremio:
Kafka per Seacom rappresenta non solo un “classico” sistema message broker, ma una vera piattaforma di stream processing, che permette di processare dati durante il flusso, che, con l’aggiunta di KSQL, consente anche l’interrogazione di questi dati con semantica sql.
Dremio è una piattaforma di data virtualization e data lake engine che consente un accesso ai dati facilitato e migliorato nelle performance, senza dover spostare i dati originali dalle rispettive strutture dati (silos, data lake). Per maggiori info potete fare un salto sul tema del mese di Aprile, dove ne abbiamo parlato nel dettaglio.
Fino a questo momento era impossibile connettere direttamente Dremio e Kafka, mentre per altri servizi era già disponibile un connettore dedicato (come nel caso di elasticsearch).
Il connettore Kafka – Dremio è quindi entrato a far parte dei progetti legati a Xstream Data, una business unit dedicata allo sviluppo di sistemi avanzati di gestione dati e architetture big data.
In questo articolo andremo a spiegare cos’è ksqlDB, per approfondirlo poi tramite un video che mostra il funzionamento del connettore Dremio – ksqlDB. Per avere una introduzione a Dremio rimandiamo all‘articolo che introduce Dremio.
Le caratteristiche di ksqlDB
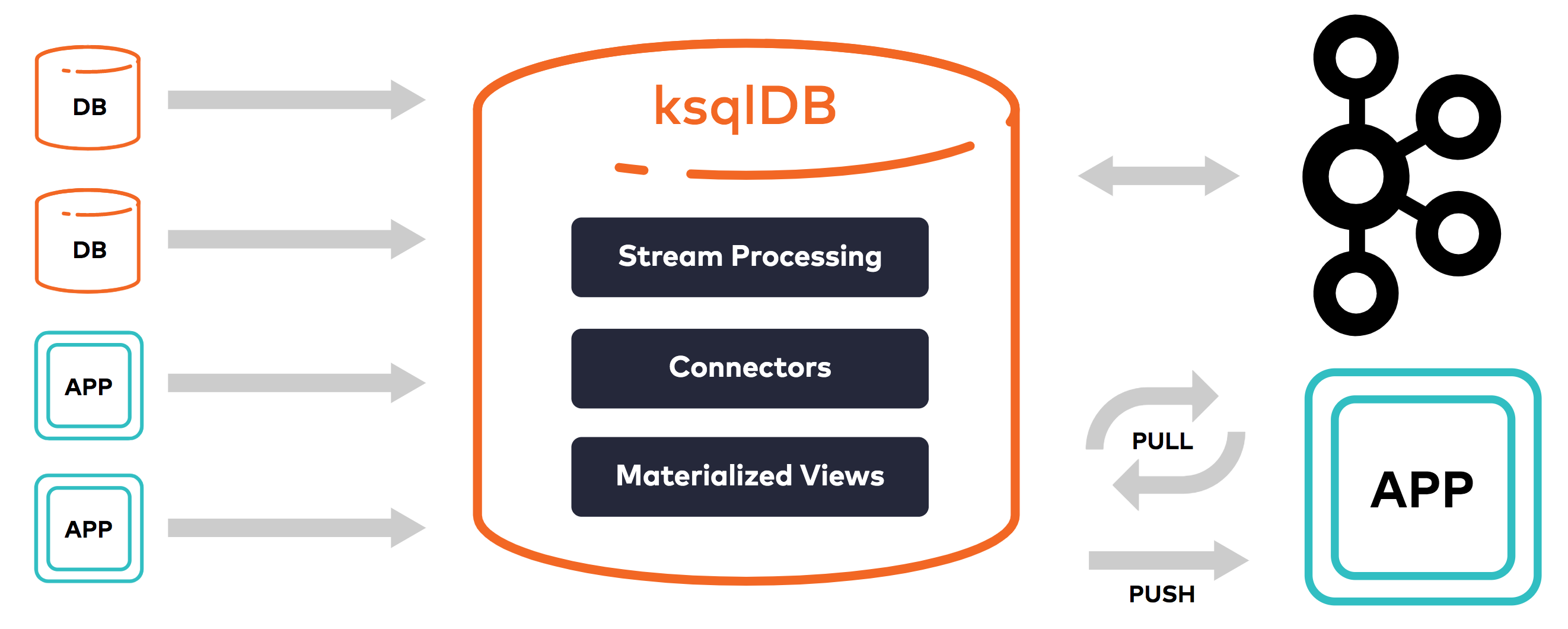
ksqlDB non è nuovo: è la continuazione dello sviluppo di KSQL, un prodotto che esiste già da metà 2017 e che ha cambiato nome solo di recente.
Oltre al cambio di nome, ora il prodotto è sotto licenza Confluent Community e se prima le query SQL restituivano tutte un flusso di dati continuo, adesso queste hanno anche un nome in ksqlDB: Push Queries.
ksqlDB introduce le Pull queries, le quali permetterebbero di prendere i dati in un punto specifico nel tempo, come se stessimo interrogando un RDBMS(Relational Database Management System).
Al momento questo tipo di query presenta una serie di limiti: ad esempio. si
possono eseguire solo su tabelle materializzate create utilizzando funzioni di
aggregazione.
ksqlDB è un database per lo streaming di eventi ideato per creare applicazioni di
streaming su Kafka utilizzando query SQL. Sempre sul sito di Seacom troviamo
un articolo che introduce Kafka con i relativi casi d’uso.

ksqlDB è una API di alto livello rispetto alle Kafka Streams e quest’ultime lo
sono a loro volta rispetto alle API dei consumatori e produttori.

Applicazioni e vantaggi
ksqlDB riduce la complessità richiesta nel creare applicazioni di stream processing grazie alla semplicità d’uso delle query SQL rispetto al creare applicazioni Java o Scala utilizzando Kafka Streams. Le componenti principali di ksqlDB sono le collezioni, le viste materializzate (Materialized Views) e le query. Vedremo poi che ksqlDB fornisce anche un’integrazione con Kafka Connect.
Le collezioni disponibili sono le Stream e le Table. Entrambe sono rappresentazioni logiche dello stesso dato fisico presente in un topic. Operano con un modello chiave-valore. Le Stream sono immutabili, append-only. Sono utili per rappresentare una serie di fatti storici. Le Table sono mutabili, consentono di avere l’ultima versione di ciascun valore per ogni chiave. Servono a modellare le modifiche nel tempo e sono spesso utilizzate per rappresentare aggregazioni. È possibile creare una collezione su un topic di Kafka esistente con una dichiarazione DDL (Data Definition Language) oppure su un nuovo topic con una dichiarazione DML (Data Manipulation Language).
DDL (dichiara qualcosa come una entità logica): CREATE TABLE/STREAM name
(schema …) WITH (kafka_topic=’topic’);
DML (crea nuovi dati con un nuovo topic): CREATE TABLE/STREAM name
(schema …) AS SELECT * FROM source;
La marcia in più delle Materialized View
Il tipo DML appena presentato, se abbinato a una funzione di aggregazione, ci permette di creare una vista materializzata (Materialized View). Un esempio completo è presente sulla documentazione di ksqlDB. Si tratta di un approccio
per elaborare in anticipo i risultati di una query e memorizzarli per un successivo accesso in lettura, in maniera rapida. Contrariamente a una normale query, che fa tutto il suo lavoro in fase di lettura, una Materialized View fa tutto il suo lavoro in fase di scrittura. Il vantaggio è che viene valutata una query solo sulle modifiche effettuate, non sull’intera tabella. Le Pull Queries di cui parlavamo all’inizio consentono di ottenere lo stato corrente di una Materialized View in tempi molto rapidi e sono adatte a modelli di applicazioni a domanda e risposta.
Integrazione con Kafka Connect
ksqlDB include un’integrazione nativa con Kafka Connect fornendo un’interfaccia SQL nell’utilizzo dei connettori.

Kafka Connect è un framework per copiare dati da Kafka verso altri sistemi e viceversa. In Kafka Connect troviamo vari componenti: i Connectors (connettori) definiscono da dove (Source Connectors) o dove (Sink Connectors) devono essere copiati i dati, i Task (attività) effettuano la copia dei dati, i Converters (convertitori) vengono usati dai Task per cambiare il formato dati binario in un formato interno a Kafka Connect e viceversa. Parte del loro lavoro quindi è quello di serializzare e deserializzare dati. Esempi sono AvroConverter, JsonConverter, StringConverter, ByteArrayConverter (nessuna conversione).
Kafka Connect non è l’unica alternativa per fare questa copia dei dati, è sempre possibile utilizzare le API dei produttori e consumatori di Kafka, ad esempio creando degli script Python che utilizzino queste librerie.
Di recente Dremio si è espressa a riguardo l’utilizzo di Kafka come sorgente dati in un articolo. In poche parole un possibile approccio sarebbe quello di estrarre i dati da Kafka e di inserirli in formato csv nello storage di Amazon S3 utilizzando uno script python per il consumo dei dati da Kafka. Dopodiché viene consigliato di interrogare i dati presenti in Amazon S3 con una versione di Dremio ottimizzata per Amazon chiamata Dremio AWS Edition. L’estrazione dei dati da Kafka a Amazon S3 è possibile anche con l’ausilio di ksqlDB, installando il connettore S3 Sink ed eseguendo una query avente sintassi
CREATE SINK CONNECTOR connector_name WITH (
’connector.class’ = ’io.confluent.connect.s3.S3SinkConnector’,
property_name = expression [, …]
Nel video che vedremo fra poco, riprenderemo l’esempio utilizzato da Dremio
nell’articolo, dove al posto di utilizzare S3 e il connettore Dremio – S3, utilizzeremo ksqlDB e il connettore Dremio – ksqlDB sviluppato da Seacom.
Fonti:
www.confluent.io: blog/ksql-streaming-sql-for-apache-kafka, intro-to-ksqldb-sql-database-streaming , /confluent-community-license-faq/
docs.ksqldb.io/en/latest/, docs.confluent.io/current/connect/concepts.html
Fonti immagini:
https://docs.ksqldb.io/en/latest/concepts/ksqldb-and-kafkastreams/
https://docs.ksqldb.io/en/latest/
https://docs.confluent.io/current/connect/concepts.html
Vuoi saperne di più?
Se desideri approfondire l’approccio Data Streaming e conoscere nel dettaglio vantaggi e potenzialità di Apache Kafka contatta Seacom.