
Nel seguente articolo vedremo come è stato usato Graph, il nuovo plug in dello stack elastic per Elasticsearch e Kibana, per esplorare le relazioni relative ai dati di Twitter in riferimento alla campagna politica di Donald Trump. Una grande fonte di dati gratuiti da utilizzare con Graph provengono appunto da Twitter e Logtash ha di default un sistema di raccolta di dati che provengo appunto da questo social. L’imput di Logtash relativo a Twitter monitora costantemente il feed per un preciso termine di ricerca, che nel nostro caso è la parola “Trump”.Lasciando girare Logtash sul pc per circa un’ora, si è in grado di raccogliere un migliaio di tweets da far analizzare a Graph.
Di solito quello che si vuole misurare su Twitter è quanto gli hashtags sono popolari e quali di questi sono usati insieme frequentemente. Come azienda, ottenere questa informazione può aiutarvi a massimizzare la vostra presenza nei social media.Capire quanto un hashtag sia utilizzato è un attività abbastanza banale con Kibana; la cosa cambia se si vuole capire quanto frequentemente gli hashtags vengono usati insieme. Quali persone usano questi hashtags nelle loro conversazioni? Questo è il momento in cui entra in gioco Graph. Utilizzando il plug in Graph con Kibana per ricercare “#Trump” immediatamente viene prodotto un grafo che rappresenta le interconnessioni fra gli hashtags.
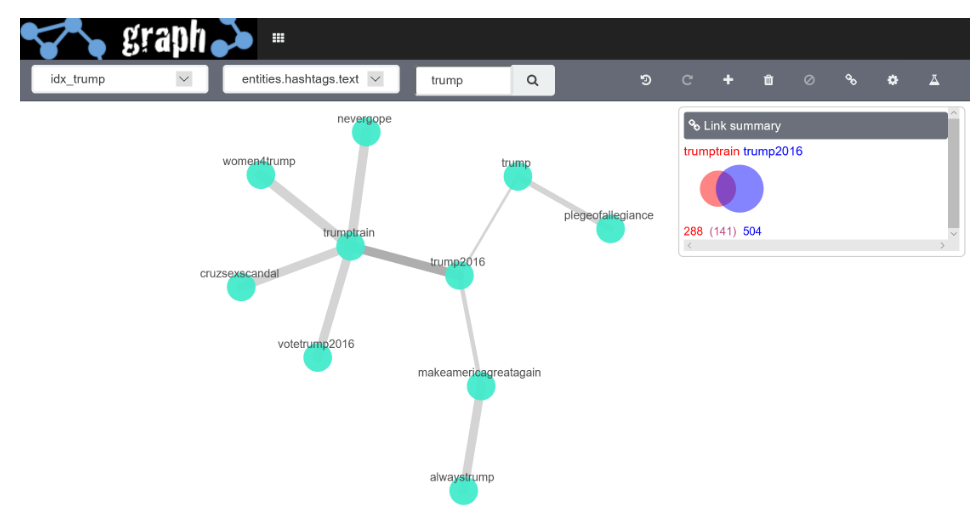
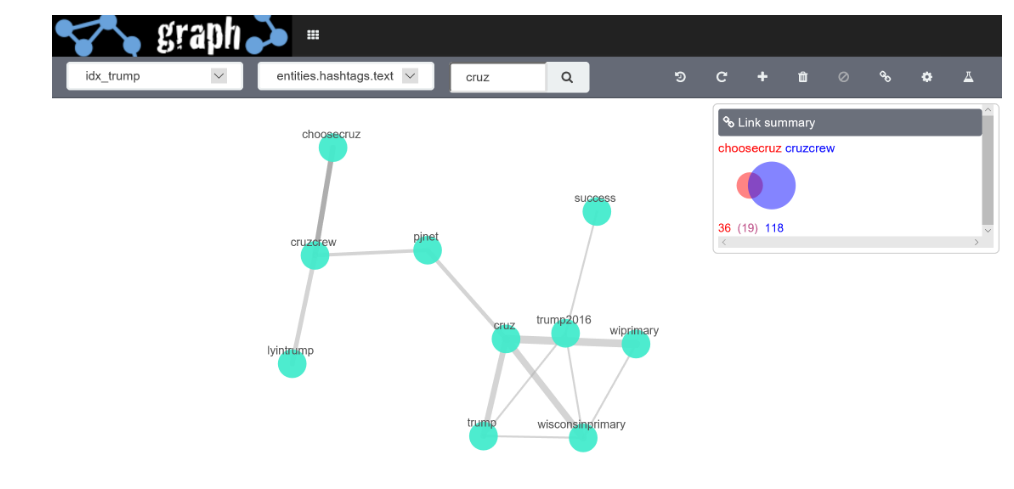
Graph ci mostra subito gli hashtags più popolari associati alla campagna presidenziale di Trump e collega fra loro quelli che vengono spesso utilizzati insieme. Al contrario se si cerca l’hashtags #Cruz per il dataset vengono fuori delle impressioni completamente diverse.
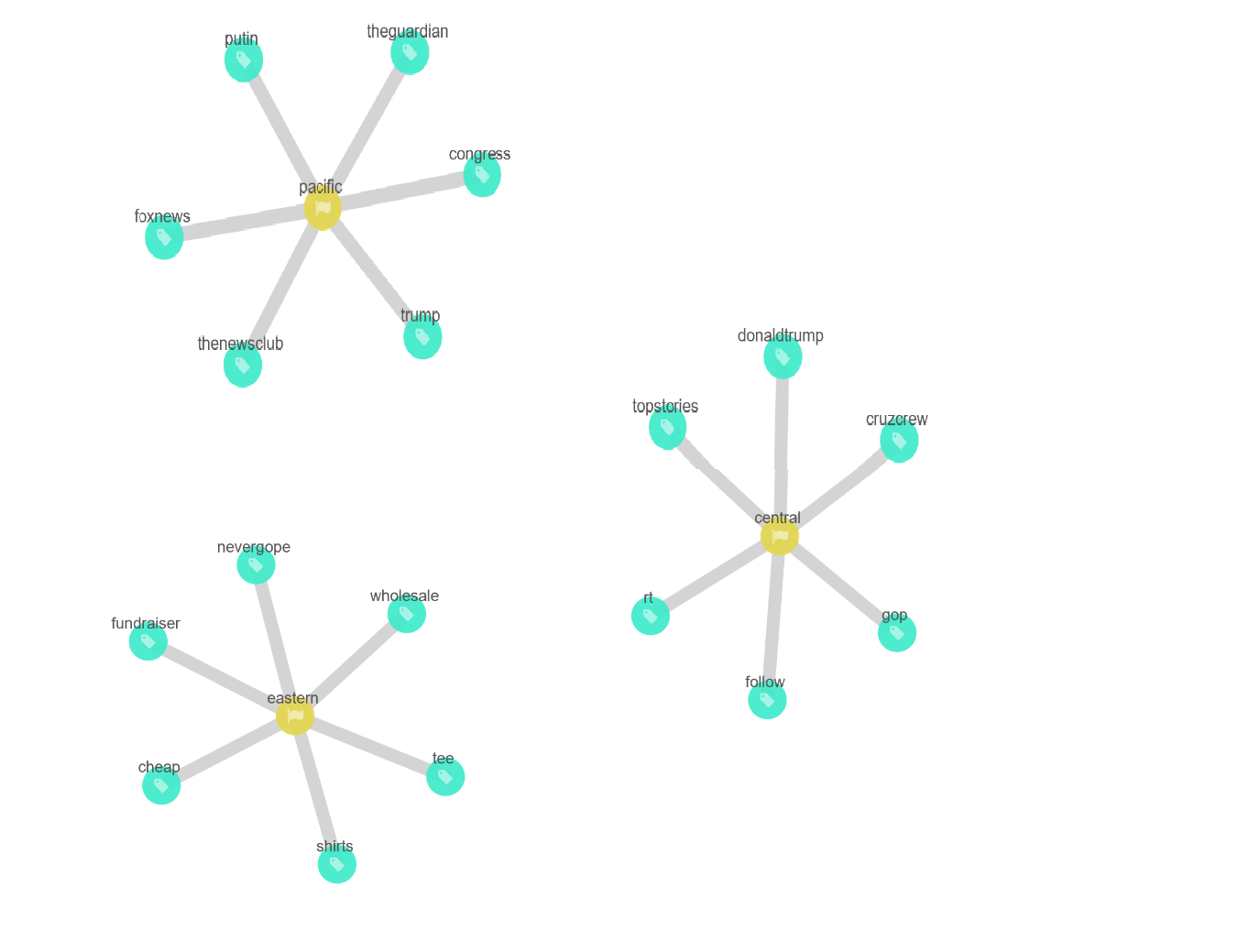
Utilizzando le funzionalità avanzate di Graph, non solo è possibile individuare le connessioni tra hashtags ma anche tra hashtags e altri tipi di dati. Un buon esempio di questa funzionalità è categorizzare l’America in base al fuso orario, dividendo il nostro campione in tre gruppi e vedere quali hashtags sono più comuni in base al fuso orario.
I tipi di dati forniti da Logtash hanno un gran potenziale e possono fornire dettagli su argomenti che altrimenti sarebbero veramente difficili da comprendere; in questo caso ad esempio, siamo in grado di leggere il contenuto grezzo dei tweet e le parole più comunemente associate, come ad esempio le parole usate dagli utenti di twitter per descriversi.
Un ambito in cui lo strumento di analisi dei feed di logstash per Twitter è carente è l’analisi dei followers. Cosa succede per esempio se io voglio sapere su quali ambiti certi utenti sono popolari e a quali altri utenti sono interessati i loro followers?Fortunatamente Logstash riesce in modo semplice a leggere qualsiasi tipo di file quindi è semplice utilizzare le API di twitter per restringere il campo dei dati a cui siamo interessati e passarli a Logstash.
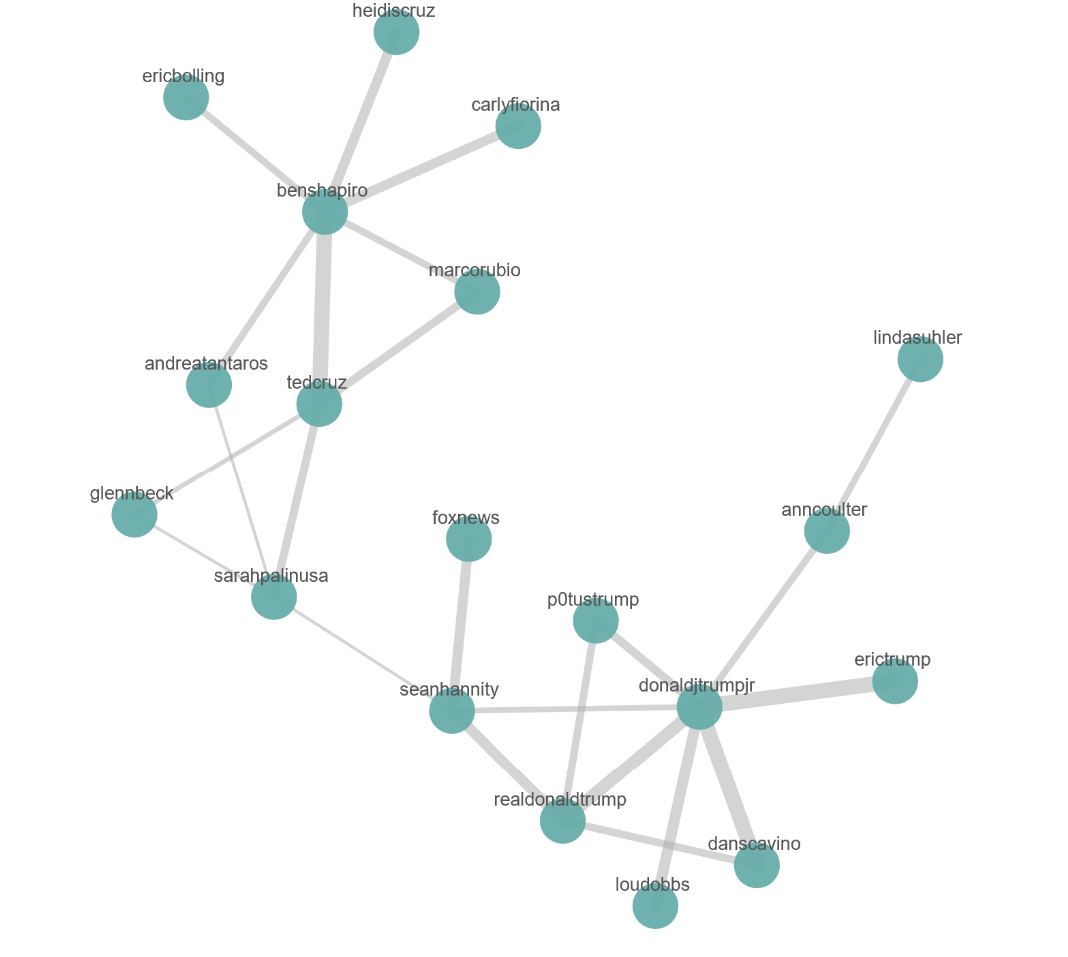
Di conseguenza è possibile costruire un grafo in grado di mostrare i trends più comunemente seguiti; nel grafo, lo spessore delle linee mostra la forza delle connessioni.
Ovviamente Graph è uno strumento potente in grado di individuare utenti chiave, connessi e anche utenti simili in modo semplice e veloce.
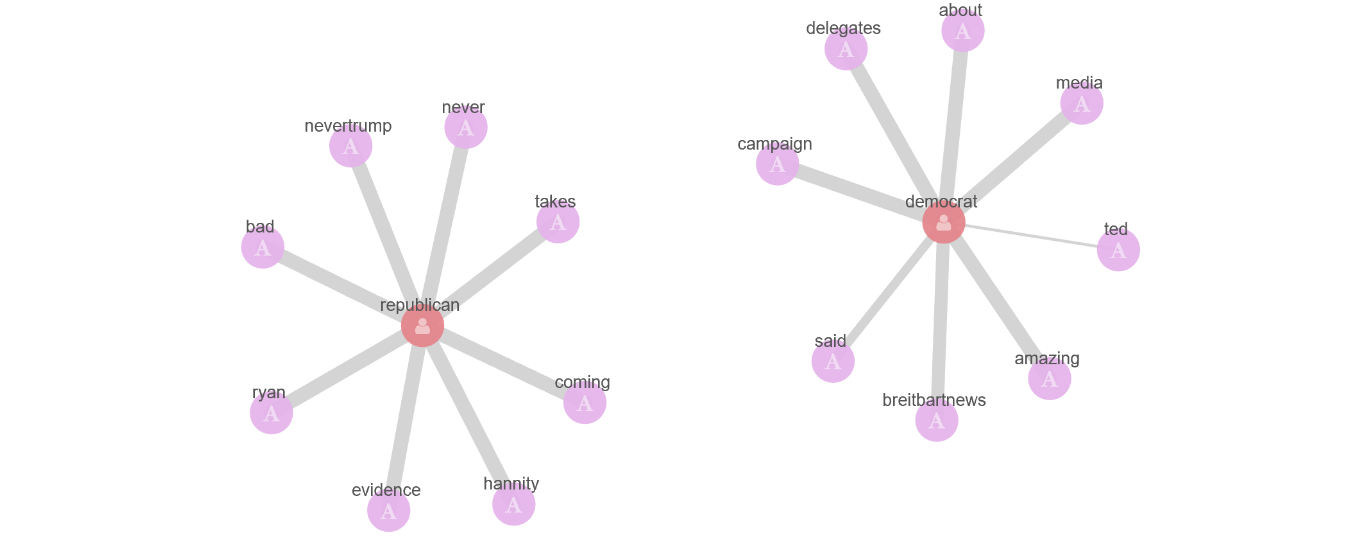
Un altro problema che potrebbe emergere nell’analisi dei grafi è rappresentato dalle ripetizioni dei dati provenienti da una stessa fonte. Per esempio, se un utente twitta un centinaio di volte più di altri, la sua posizione all’interno del grafo sarà un centinaio di volte più influente, come quando si cerca il termine “repubblicano” all’interno dei profili degli utenti:

Qui ad esempio, ad una prima occhiata i risultati sembrano buoni, ma guardando meglio una delle connessioni risulta essere un po’ strana: tutti i repubblicani sono cowgirls? In realtà sembra più verosimile che ci sia una cowgirls repubblicana che twitta molto più frequentemente rispetto agli altri. Fortunatamente Graph ha una soluzione per questo problema: si tratta dell’opzione diversity field; è possibile infatti limitare il peso di un certo contenuto che ha lo stesso valore per un determinato campo. Nel nostro caso ha senso limitare l’importanza di un certo contenuto che proviene dallo stesso ID.
Ripetendo l’analisi con queste nuove impostazioni i risultati sono completamente diversi:
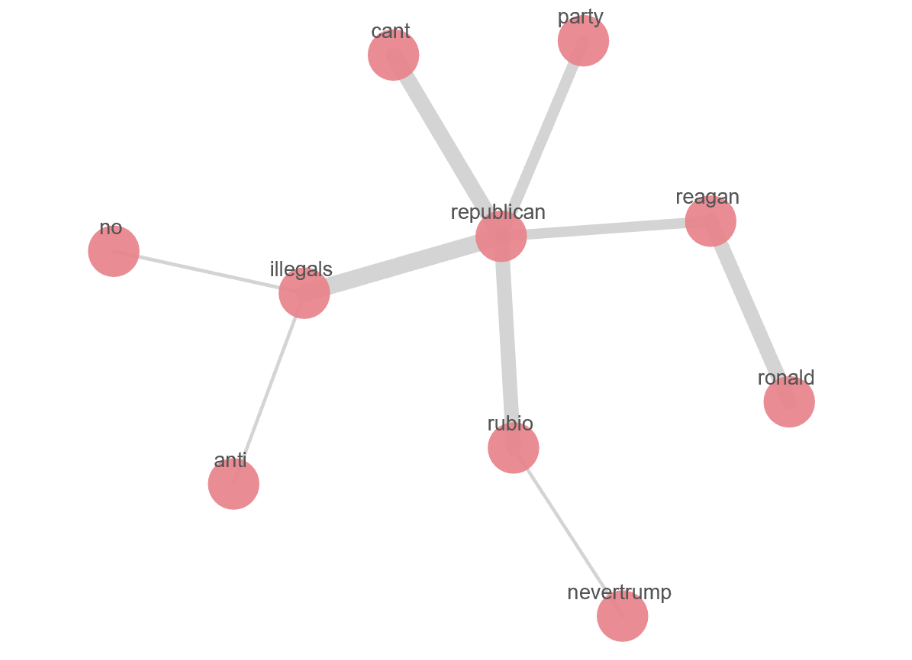
Un altro vantaggio dell’algoritmo di Graph è la capacità di filtrare termini frequenti “super connessi” e identificare esclusivamente i “link significativi”. Questa caratteristica, se ritenuto necessario, può essere disabilitata. Per esempio, ripetendo la ricerca per “repubblicano” senza “link significativi”
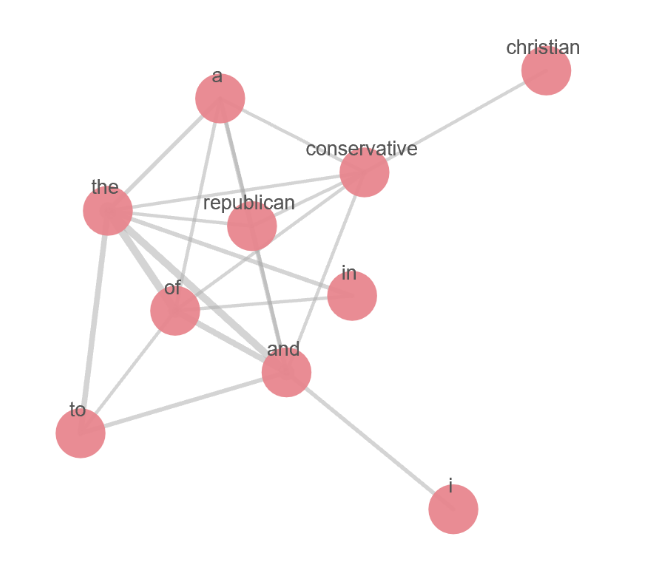
Tutte le relazioni mostrate tramite la dashboard di Kibana sono ottenute tramite query sulle API di Elasticsearch Graph. L’applicazione consente di visualizzare anche i dati JSON grezzi, rendendo semplice l’integrazione di Graph in un’applicazione custom.
Per approfondimenti sulle potenzialità di Graph contatta i nostri tecnici: [email protected]