
Utilizzare Elastic Graph + Kibana per analizzare i Panama Papers
Le caratteristiche di Elastic Graph permettono di scoprire e visualizzare eventuali correlazioni e connessioni fra dati. Sia che si tratti di scoprire accordi finanziari illeciti nei Panama Papers o visualizzare una panoramica della distribuzione dei click in un sito di E-commerce, la tecnologia di Graph aiuta a mettere a fuoco queste relazioni tra dati.
Le funzionalità di Graph sono integrate come parte del pacchetto di plugin X-Pack di Elastic Stack, comprensive della nuova versione di Kibana e delle API Elasticsearch. In questo articolo vedremo brevemente un esempio di utilizzo della combinazione tra Questi due applicativi.
Analisi Forense: i Panama Papers
Il rilascio di informazioni finanziarie e legali relativa all’azienda offshore Mossack Fonseca rappresenta uno dei temi più caldi del 2016. I documenti rivelano una serie di attività illecite associate ai nomi di politici, membri di famiglie reali, VIP e altri personaggi piuttosto influenti.
La reazione di giornalisti e istituzioni finanziarie è stata comprensibilmente travolta da questa enorme “fuoriuscita” di dati, la cui analisi e soprattutto l’identificazione di eventuali relazioni interne è immediatamente apparsa lunga e complessa.
Le app Kibana e Graph fortunatamente possono semplificare questo processo:

In questa immagine vediamo le compagnie e altri soggetti connessi a un amico stretto di Vladimir Putin, Sergei Roldugin. Questa immagine è stata realizzata seguendo alcuni semplici step:
selezione della sorgente dati
inizialmente, da una lista di indici, sono state selezionate le parole “panama” e altri campi da visualizzare nel diagramma. Ad ogni campo è stata associata un’icona e un colore che distinguerà i singoli “vertici” del diagramma.

Avvio della ricerca
È stata quindi condottaa una prima ricerca free-text con lo scopo di ottenere un matching dei documenti contenenti il nome “Roldugin”.

I termini rilevati nei documenti sono rappresentati come un network, dove ogni linea rappresenta uno o più documenti che collegano una coppia di termini.
I giornalisti di ICIJ che hanno gestito i dati hanno cercato di attribuire a ciascuna entità “reale” (persona, azienda, indirizzo) un ID univoco, collegato a ciascun documento in cui viene fatto riferimento ad esse.
Sfortunatamente nomi di persona e indirizzi sono difficili da identificare – i giornalisti hanno correttamente identificato 3 documenti connessi a entità-persona 12180773, ma possiamo notare la presenza di altre due persone con nomi simili ma codici identificativi differenti. Allo stesso modo sono presenti due indirizzi simili con diverso ID.
Raggruppamento dei vertici
Utilizzando gli strumenti avanzati di Graph è possibile selezionare i vertici. Premendo “group” questi vengono aggregati fornendo un’immagine più chiara:

È inoltre possibile aggregare vertici già raggruppati, come nel caso in cui si volesse identificare entità-persona con più identificatori in singoli nodi per poi effettuare il merging con le entità-azienda.
È quindi possibile continuare l’esplorazione utilizzando il tasto “+” nella toolbar per introdurre ulteriori entità:

Premendo ripetutamente il tasto “+” e i controlli di selezione è possibile espandere e analizzare nel dettaglio aree specifiche del grafo. I controlli per la cancellazione e “blacklist” dei risultati aiutano a controllare la visibilità degli item interessanti. Possono inoltre essere mostrati gli snippet dei documenti relativi ai nodi selezionati.
“La saggezza delle folle”
I Panama Papers sono un’empio di investigazione di tipo forense, in cui ogni singolo documento più rappresentare un’importante connessione.
Elastic Graph eccelle nella capacità di riassumere dettagli relativi al comportamento degli tenti, come nel caso dell’analisi dei click o dei log.
Per identificare questo tipo di analisi si usano solitamente le locuzioni “intelligenza collettiva” o “saggezza delle folle”. In questi scenari, ogni documento analizzato non è di per sé interessante o informativo, mentre l’identificazione di pattern di comportamento di un certo numero di utenti può rivelarsi fondamentale. Da questo tipo di analisi possono essere tratte delle inferenze, ad esempio: “clienti che comprano il prodotto X comprano anche il prodotto Y”. In questi scenari è necessario evitare tutti quei documenti irrilevanti ai fini di un’analisi globale, così come eliminare le associazioni tra entità fin troppo evidenti (es: chi compra il prodotto X compra anche il latte. Irrilevante dal momento che praticamente tutti comprano il latte).
Le impostazioni di base di Graph sono settate in modo tale da evitare questo comportamento e rilevare soltanto le connessioni più informative.
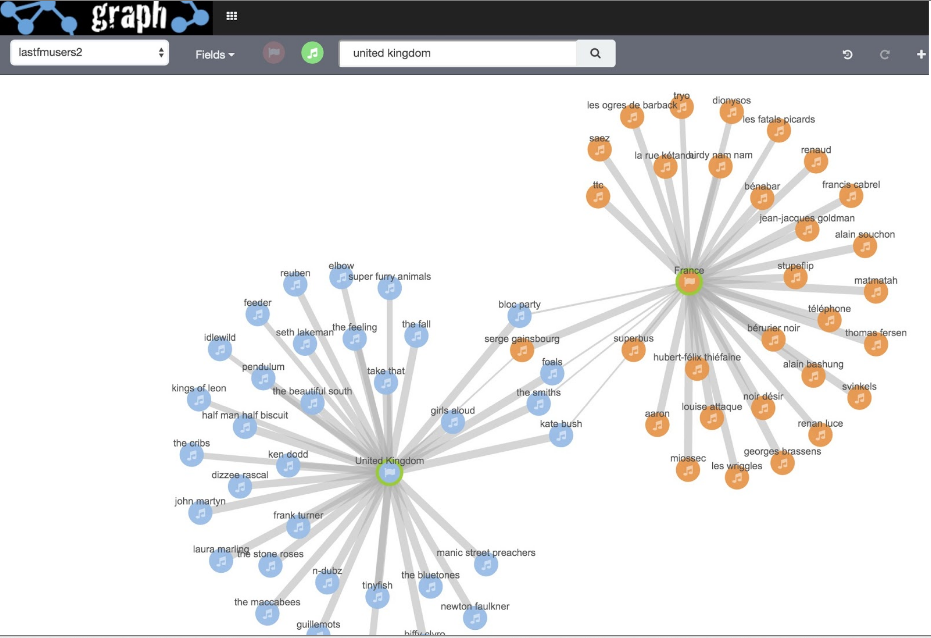
Use case con LastFM dataset:
se si costruisce un indice con focus sugli utenti, si ottiene un singolo documento per ascoltatore contenente un array dei relativi musicisti preferiti. Ecco cosa si ottiene effettuando una query su questo indice: “persone a cui piace Chopin”:

Gli artisti classici correlati sono abbastanza ovvi. Facendo click su un collegamento è possibile rilevare quanti ascoltatori condividono uno specifico artista. Per esempio, a circa la metà di ascoltatori di Chopin piace Felix Mendelssohn.
Le API di Elastic Graph hanno individuato solo le associazioni significative. Questa è una differenza importante rispetto a molte altre tecnologie di esplorazione dei grafi.
Popolare != Significativo
Vediamo cosa succede se viene disabilitata l’opzione che rileva slo i risultati importanti:

Disabilitando l’opzione, la query relativa a Chopine produce un output decisamente diverso:
Si noti l’introduzione all’interno del grafo di vertici associati ad artisti come Radiohead e Coldplay. Tra i 5721 fan di Chopin, 1843 sono anche fan dei Beatles. Questo dato, classificato come “commonly common”, non è molto diverso dal precedente esempio dei clienti che comprano il latte.
Abilitando l’opzione “significant link” si elimina quindi il rumore dei dati, focalizzandosi maggiormente su risultati “uncommonly common”. Il principio di base che regola questo comportamento è rappresentato dall’algoritmo TF-IDF, che da anni è alla base dei più comuni motori di ricerca.
Utilizzando questa tecnica basata sulla rilevanza dei documenti è possibile rimanere concentrati sul concetto chiave di una ricerca, durante la fase di esplorazione dei dati. Questa è una distinzione significativa rispetto a database a grafo che non implementano i concetti di relevance ranking e sono tipicamente forzati alla cancellazione di item ricorrenti (a tal proposito, si veda il problema dei “supernodi”).
Fonte: Elastic Blog
Contatta Seacom
Vuoi rimanere aggiornato su tutte novità Elastic o richiedere una consulenza a Seacom?
Visita la pagina dedicata, oppure